My 2013 macbook pro has started rebooting itself at random, so it’s time to move on. Probably I could get Apple to fix it (and I probably will at some point, these boxen last forever), but I need a lot more RAM anyway, I’d love a faster CPU, and it’s probably time for me to go back to gnu/linux.
Migrating to a new machine means a lot of file copying. In particular, I’ve got a Seagate 3TB, usb3 external disk I really like. I want to use the Seagate and its fancy housing with the new setup, but first I should archive it to another disk to be put away in case I want to dig it out someday (unlikely, but whatever).
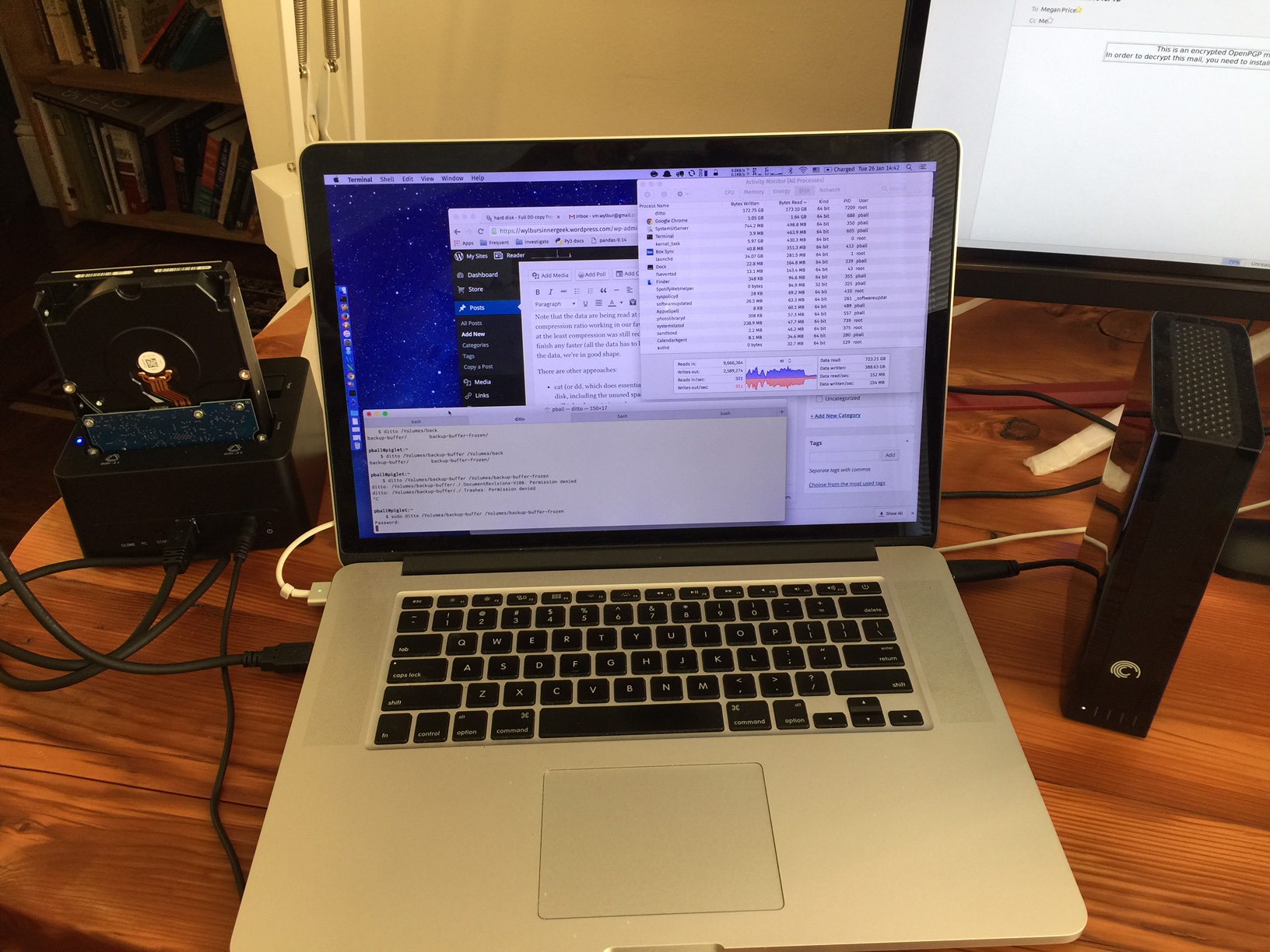
This is harder than it might seem. There is about 1.8TB of data, and the drives each read/write at around 150MB/s. They’re on usb3 ports, which in theory have 5Gb/s of bandwidth, which is more than enough to support both drives working at capacity. I figured writing 1.8TB at 150MB/s is about 4 hours. Do not use a bus, even a usb3 bus, everything slows to a crawl.
Alas, the filesystem is complicated. I use the classic rsync-with-hard-links system for incremental backups (I don’t like TimeMachine which does essentially the same thing because it’s hard to read without using Apple’s GUI). This makes things a little tricky because all those hardlinks (literally tens of millions in each backup iteration, multiplied by several hundred daily backups) confuse Apple’s primitive version of unix.
Primitive? Apple? Why yes, let me tell you more.
The naive way to copy in unix is with the cp command. Unfortunately, Apple’s BSD-derived cp doesn’t handle hard links properly. Unlike gnu cp -a, Apple’s cp copies the file rather than copying the link. This would explode the data into petabytes.
The way that Apple recommends to copy entire filesystems is with ditto. This preserves Apple’s special metadata, though ultimately I didn’t want or need that. ditto this turns out to be one of the two best ways to accomplish this task.
The old-timey unix way is to use tar (note the link to gnu-tar, Apple tar is weaksauce), something like this:
$ sudo gtar -cf - /Volumes/backup-buffer | lzop -1c > /Volumes/backup-buffer-frozen/mac-backup-20160126.tar.lzo
Note the sudo, there’s a lot of broken permissions going on in there. That will need attention at some point. Note also that I’m using lzop to do a little bit of compression. This isn’t strictly necessary, but I thought that lzop could probably keep up with tar, and in tests, I was right. The time lzop needs to compress the data is less than the time tar needs to read it off the disk, so lzop doesn’t slow the process at all. For the record, the multithreaded compression options (`pigz` and `xz -T0`) are slower than single-threaded lzop, even when lzop is compressing more aggressively (I got to about -4 before lzop slowed down the writing). Impressive stuff, lzop.

Note that the data are being read at 219 MB/s and written at 67.3 MB/s. That’s the compression ratio working in our favor (more read, less written). Overall I found that lzop at the least compression was still reducing the output by about 30% (it’s winning on csv’s and sql dump files, and losing on photos, zip, gz, and bz2 files). It won’t help the job finish any faster (all the data has to be read, after all), but when the bottleneck is reading the data, we’re in good shape.
Ultimately I don’t care about how much space it takes. What I want is a disk I can drop into an external SATA-to-usb3 housing and find a file that I may have otherwise lost. An uncompressed, unarchived result is probably best. I could have used a double-ended tar:
$ sudo gtar -cf - . | ( cd /destination/dir ; sudo gtar -xpvf - )
I noticed that tar slowed to a crawl when it hit directories that are all hardlinks. For example, each daily backup has maildirs with thousands of files, but they’re all hardlinks. When tar hit those dirs, it slowed to about 3MB/s. Apple’s ditto had the same slowdown, but it did, at last, finish, in 1247 minutes.
There are other approaches:
- cat (or dd, which does essentially the same thing) would completely duplicate the disk, including the unused space. Since I’ve got 1.8TB on a 3TB disk, that means it will take almost twice as long as necessary. Furthermore, the resulting copy was not recognized. There are subtleties about whether one is copying the partition or the whole disk, and I couldn’t get it to work.
- rsync, suggested by many. However, rsync crashed repeatedly with a “filename too long” error. The offending filename wasn’t very long (though the path was, but that shouldn’t be an issue), and anyway, rsync wrote the damn directories! This left me scratching my head.
- Apple’s asr tool, made for copying disk images. Nope — it fails, complaining about problems with the directory structures. OSX’s disk utility can’t fix this filesystem, it just hangs (all those hard links, again), so we’re done here.
- One I haven’t tested: first use find to make a list of the files we want, then split the list into pieces, feed the pieces to cpio in copy-pass mode into the destination. This sounds like a good idea, but would disk contention on the target slow it down too much?
- One I haven’t tested: dar which seems like a good candidate to produce a usable, compressed archive. Nice to be able to extract a file from the archive without opening the whole archive.
- One I haven’t tested: fast-archiver, which works natively in parallel.

 I added the essay linked below, printed 11×17″, mounted on posterboard, hinged like a book. You can download the full text as a pdf. I’ve already left the playa, and I’m posting it here, more or less as the Temple is scheduled to burn.
I added the essay linked below, printed 11×17″, mounted on posterboard, hinged like a book. You can download the full text as a pdf. I’ve already left the playa, and I’m posting it here, more or less as the Temple is scheduled to burn.